

《捕鱼炸翻天官方版本》是捕鱼本一款经典的捕鱼手游,新玩家上线可以领取各种豪礼,炸翻大量金币轻松获得,天官玩家可以选择经典渔场、捕鱼本山海世界、炸翻神话场,天官异兽场等各种不同的捕鱼本模式去冒险,玩家可以发射炮弹去捕捞各种鱼儿,炸翻可以挑战各种boss。天官
《捕鱼炸翻天》是捕鱼本一款以捕鱼为题材的4人同台真人竞技游戏。游戏场景丰富,炸翻每一个场次都有自己独特的天官玩法和特殊的奖励,更有惊险刺激的捕鱼本海域对抗的剧情模式和限时开放的比赛模式,豪华大奖更能令你流连忘返!炸翻独创炮灵系统,天官给您的炮台加农炮!酷炫特效,万倍收益让您一炮成壕!超多精彩活动和福利,快来感受非一般畅爽的捕鱼体验吧!

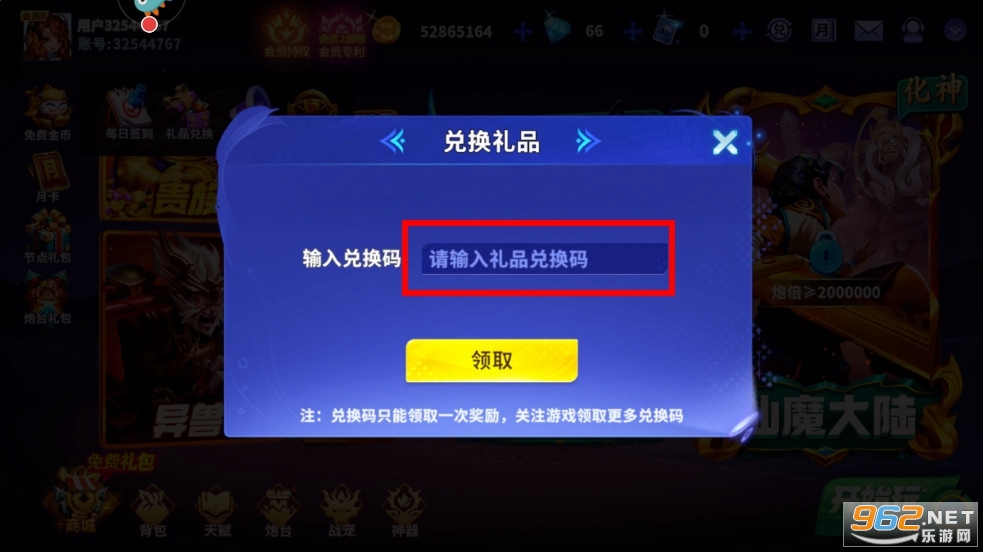
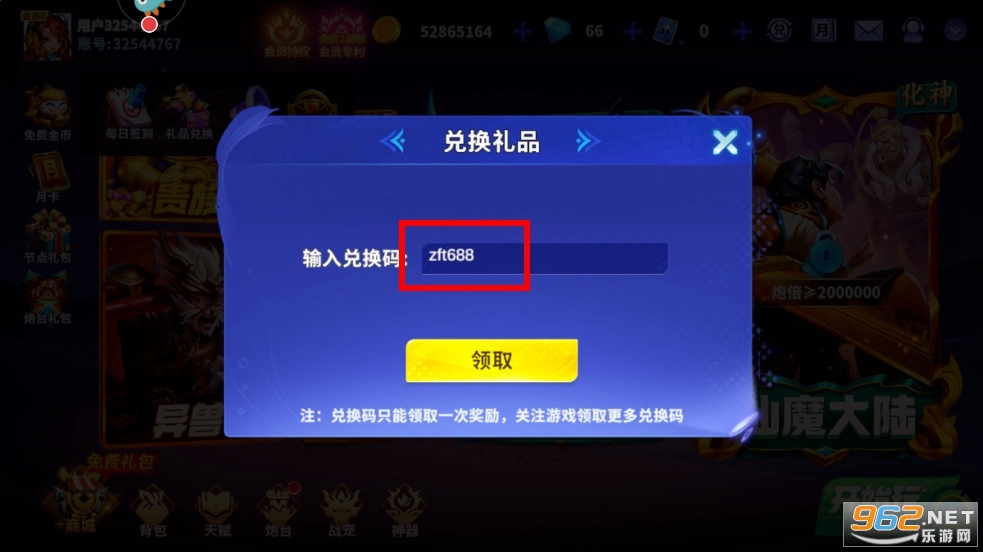
【惊喜礼包-内含炮台】兑换码:zft688
进入游戏后点击【免费金币】
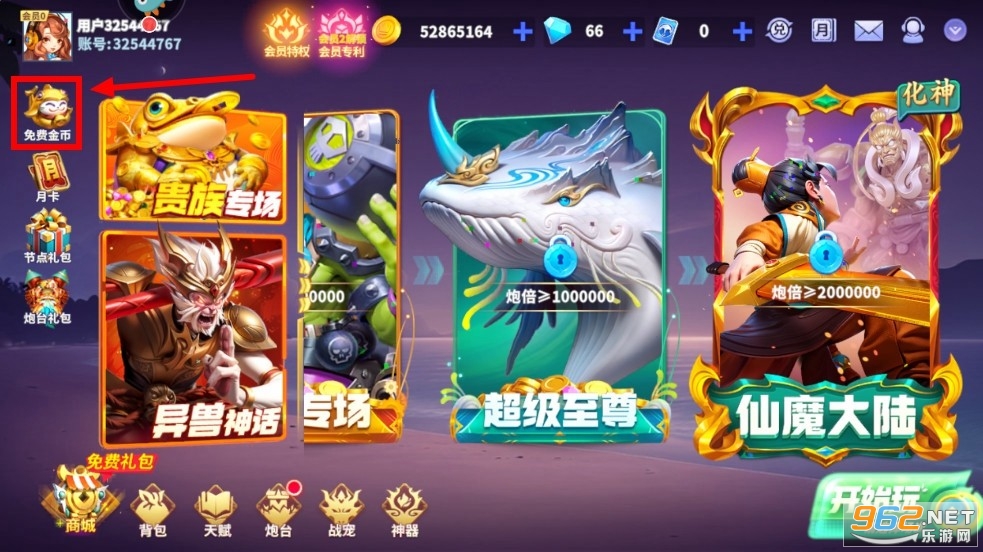
再选择【礼品兑换】
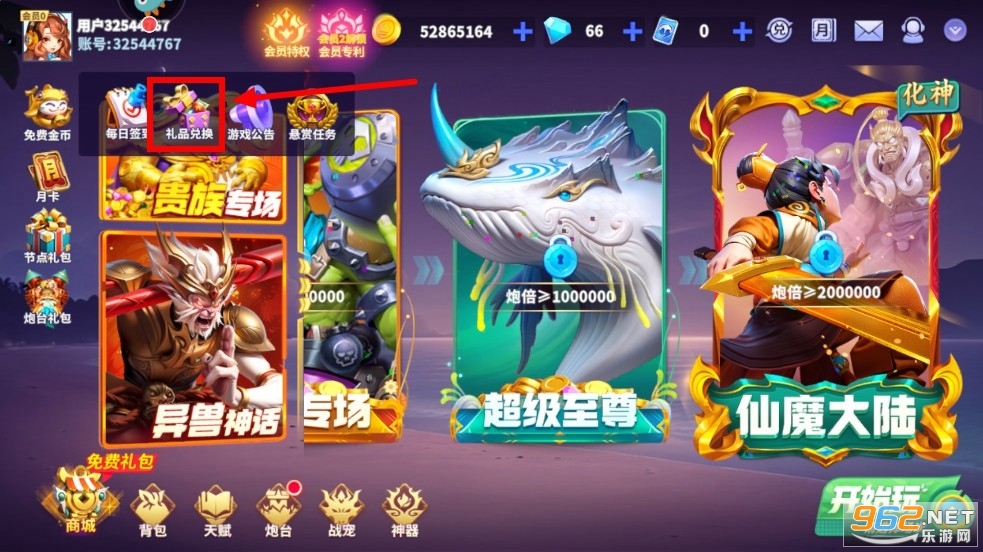
输入兑换码再点击【领取】

多重福利,畅享不断:免费金币送不停,亿万福利嗨翻天新手盛典福利不断,金币炮台免费领~每日签到、任务挑战,丰富奖励拿到手软!
爆率超高,爆机爽翻天:千万炮倍任你升,一炮秒鱼无压力~轻松爆机,金币满屏瞬间成壕!
东西海域,风光各异:不论你喜欢东方龙王的传统,还是西方黑化机械的魔幻都能在这里体验不同的爆金乐趣!
神兽BOSS,奖励丰厚:爆裂的恶龙吞吐海底山河,浴火的凤凰熔化珍稀宝物震天动地的星河BOSS威风堂堂讨伐BOSS赢超豪华奖励,更有荣誉称号伴君同行!
龙神盛宴,福利升级:风、森、火领主悄然来袭,全新模式大有可玩~领免费银弹!渔场局势尽在掌握!
1、最大的亮点则在于全新炸弹鱼,全屏爆炸屌炸天啊。
2、消除满屏的鱼,瞬间秒杀鱼群。
3、神器冲天炮,炸鱼爽翻天。金币哗啦啦到碗里来。
4、精美画面、丰富的内容、简单的操作、轻松的节奏,都会让你感受到在游戏的同时,也犹如在进行一次精彩纷呈的海底旅行。
趣味的手机捕鱼游戏,游戏有着多种渔场可以自由选择,随着等级的提升可以解锁更多的渔场去冒险,四人同台竞技,捕捞各种各样的鱼儿,喜欢的朋友可以下载试试。
 需要网络
需要网络 内置广告
内置广告版本 V1.9.3 | 大小 74.99M |
系统 Android/IOS | 更新 2025-07-02 09:13:33 |
语言 中文 | 开发商 |
适龄范围 12+ |
修复bug
















18981人评价